
Cellular alchemy
How solving the epigenome will let us create every healthy cell in the body


Transmuting lead into gold. Brewing elixirs of immortality. Ancient alchemists sought nothing less than mastery over matter itself. Their quest rested on three bold convictions: all things could be reduced to fundamental elements; these elements, precisely combined, could yield any substance imaginable; and hidden within this material landscape lay the philosopher's stone, a mythical state capable of extending life.
Though we now know the alchemists were misguided, I can't help but admire their audacious spirit. Mixing mysterious concoctions in their crucibles, these early experimenters unknowingly paved the way for modern chemistry and understanding the true building blocks of matter. Ironically, their greatest oversight was not their ambition in seeking eternal life, but their failure to recognize that nature’s most powerful transmutation engine was inside them all along, residing within their very own cells.
I: The modern alchemists
“You start out as a single cell derived from the coupling of a sperm and an egg; this divides in two, then four, then eight, and so on, and at a certain stage there emerges a single cell which has as all its progeny the human brain. The mere existence of such a cell should be one of the great astonishments of the earth. People ought to be walking around all day, all through their waking hours calling to each other in endless wonderment, talking of nothing except that cell.”
– Lewis Thomas, The Medusa and the Snail
I watched it begin again
In 1962, John Gurdon performed the first act of cellular alchemy. Using an ultraviolet microscope, he first removed the nucleus (the compartment containing the genome) from an unfertilized frog egg. Then with a glass needle, he extracted another nucleus from a tadpole intestinal cell and placed it into the emptied egg. To the naked eye, nothing seemed to happen—the modified egg simply developed into an ordinary frog. Yet this deceptively simple experiment solved one of biology's greatest mysteries.

The process of development is generally a one-way street. A single fertilized embryo divides into two cells, then four, then eight, gradually building a complex organism. As this process unfolds, each cell's range of potential fates steadily narrows. At a cellular level, this narrowing is known as differentiation. While an embryonic stem cell can become any cell type in the body, neural stem cells produce only cells of the brain and nervous system, and mature neurons permanently remain neurons. Eventually, most cells fix their identity and stop dividing altogether, becoming what biologists call mature or terminally differentiated. It's akin to human life stages: babies have limitless possibilities, college students choose specialized majors, and sixty-year-old professionals are unlikely to change careers.
But how does differentiation occur? In Gurdon’s time, one prevailing hypothesis claimed that maturing cells permanently lost the genes required to become other cell types. Perhaps neurons physically discarded genes needed for skin cells. But Gurdon's experiment shattered this theory by revealing that the complete blueprint for building a frog remained intact, tucked away inside the nucleus.
Even more astonishing was what happened inside that modified egg. The genome, previously configured to be an intestinal cell, somehow sensed its new environment and reprogrammed itself to begin the development of a new organism.
Yamanaka minus one
In 2006, Shinya Yamanaka discovered the base elements of cellular alchemy. From Gurdon's experiments, scientists knew the environment of an egg could reprogram a mature cell back to an embryonic state. But this environment contained thousands of molecules potentially capable of influencing cell fate. Of these thousands, which were the magic combination?
While this particular question went unanswered for decades, researchers did make substantial progress on understanding how genes are controlled during development. Central to these findings were transcription factors, proteins that act as on/off switches for different regions of the genome.
Yamanaka hypothesized that transcription factors might also be the key to reprogramming. To test this, he selected 24 transcription factors found in embryonic stem cells and added them to skin cells growing in a Petri dish. Remarkably, over several weeks, some of these skin cells transformed into stem cells, echoing Gurdon's experiment. While these initial results were already groundbreaking, Yamanaka was determined to distill his finding to its core elements.
One by one, he painstakingly subtracted each transcription factor from his recipe. Most proved extraneous, but without others, the cells stubbornly remained skin. Eventually, he reached a stunning conclusion. Just four factors—OCT4, SOX2, KLF4, and MYC—were sufficient to reprogram ordinary skin cells into induced pluripotent stem cells (iPSCs), theoretically capable of becoming any cell type in the body.
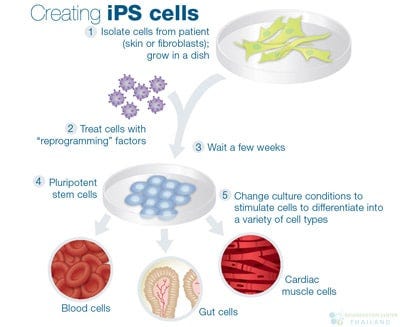
In theory, this breakthrough solved several major challenges at once. Scientists could now create stem cells for research without using controversial human embryos. Patients could also receive therapies made from their own cells, reducing the risk of immune rejection.
Yet scientists discovered one last benefit that may be the most profound. When they reprogrammed cells from elderly donors, the process shockingly erased signs of aging: re-lengthening telomeres, normalizing energy production, and clearing molecular damage. Beyond resetting cell identity, reprogramming had the astonishing power to reverse aging at the cellular level. This made perfect sense in hindsight, as Gurdon's original experiment showed that a mature cell could be made "young" enough to build a new organism. Had we discovered biology's version of the philosopher's stone?
No time like the present
Nearly two decades have passed since Yamanaka rewrote the rules of biology. So where are all the therapies? There have been isolated successes—stem cells differentiated into dopamine neurons for Parkinson’s and pancreatic beta cells for diabetes. Yet despite these promising examples, cellular reprogramming remains far from mainstream clinical practice. Given the revolutionary potential of this approach, what's holding these treatments back?
Biology's most sobering paradox is that the very mechanisms enabling life can also trigger its unraveling. Cancer epitomizes this—development requires cells to grow and divide, but the corruption of these processes results in lethal proliferation. Shortly after Yamanaka's breakthrough, researchers discovered reprogramming can inadvertently corrupt the same essential pathways, producing aggressive tumors called teratomas. This wasn’t just any side effect; it posed an existential threat to all reprogramming therapies.
Fortunately, scientists devised two clever workarounds. The key insight was to think of cells along two distinct dimensions: cell type and cell age. Cell type refers to a cell's specialized identity, such as a neuron, muscle fiber, or skin cell. In contrast, cell age reflects molecular wear and tear, often measured via DNA methylation patterns. Yamanaka-style reprogramming resets both cell type and cell age, but what if we could decouple them?

The first breakthrough was in manipulating cell type alone. Building on the discovery of a transcription factor (MyoD) that could convert cells directly into muscle, scientists adapted Yamanaka's "minus one" strategy to identify multi-factor cocktails capable of directly transforming cells into other mature types. We now have methods to turn skin cells directly into neurons or heart cells, among others, making this a promising strategy for replacing cells lost to disease or injury. Direct reprogramming minimizes tumor risk by bypassing pluripotency, but as a consequence, the resulting cells don't reverse accumulated molecular damage.
The second breakthrough, this time in manipulating cell age, arrived in 2016. Juan Carlos Izpisua Belmonte's team discovered that brief exposure to Yamanaka factors—just days instead of weeks—could extend lifespan in accelerated aging mice. Partial reprogramming can't create new cells, but it can rewind the biological clock in existing ones. Because these cells never fully revert to pluripotency, this approach also minimizes tumor risk. So, problem solved?

Today, the biggest challenge in deploying reprogramming therapies is delivery. Therapeutic strategies broadly fall into two categories: In vivo approaches resemble gene therapy, delivering reprogramming factors directly into cells within the body. In contrast, in vitro approaches are more similar to cell therapy, reprogramming cells in the lab and then transplanting them back into patients.
In vivo approaches typically use viral vectors or lipid nanoparticles (popularized by recent COVID-19 vaccines) to deliver gene payloads to specific cell types or tissues within the body. However, precisely controlling dosage in diverse cell populations remains a significant challenge. Too little yields no therapeutic effect, while too much risks tumor formation or toxicity, creating a precarious balance between efficacy and safety. To meet these challenges, the field is rapidly evolving, with companies like Dyno Therapeutics using AI to enhance viral vectors and academic scientists like Feng Zhang mining nature for new delivery vehicles.
In vitro methods offer distinct advantages, notably the ability to screen and validate reprogrammed cells before transplantation. Although generating patient-specific cells remains slow, expensive, and difficult to scale, emerging technologies such as Cellino’s autonomous cell manufacturing platform or universally immune-compatible cells could help overcome these limitations. Yet the greatest hurdle may still be biological. Despite significant effort, many clinically relevant cell types, such as functionally mature cardiomyocytes needed for heart repair, still cannot be reliably derived from stem cells without cues from the body's natural environment.
The strengths and weaknesses of these approaches add considerable nuance to discussions about reprogramming therapies. Different cell types and diseases will likely require tailored strategies, influenced by factors such as ease of delivery, the ability of targeted cells to proliferate, and the proportion of cells that must be reached for therapeutic efficacy. One useful framework is to classify strategies as rejuvenation, regeneration, or replacement. Regulatory hurdles add further complexity, especially given recent turmoil at the FDA. For brevity, this essay will focus primarily on understanding and controlling cell identity, but delivery and regulatory considerations will be critically important as we move toward real-world therapies.
Despite these challenges, the promise of cellular alchemy has sparked a modern gold rush, attracting academic researchers and Silicon Valley billionaires alike. In academia, David Sinclair's lab demonstrated that just three Yamanaka factors (OSK) could restore vision in mice with induced blindness. Wolf Reik's group showed that partial reprogramming can rewind DNA methylation clocks, now a standard in aging research even though the underlying biology remains unclear. Juan Carlos Izpisua Belmonte's team extended their original partial reprogramming results to naturally aged mice, demonstrating modest lifespan extension. And Hongkui Deng's group reported human cell reprogramming using only small molecules, potentially eliminating the need for transcription factors, though this claim has drawn skepticism due to past controversies.
Inspired by the potential to transform medicine (and perhaps live a bit longer themselves), tech moguls have poured millions into cellular rejuvenation. Altos Labs was shipped $500 million from Amazon’s Jeff Bezos, NewLimit was transferred 1,761 Bitcoin ($150 million) from Coinbase’s Brian Armstrong, and Retro Bio generated $180 million from OpenAI’s Sam Altman. Companies like Life Biosciences, Turn Biotechnologies, and Shift Bioscience are also pursuing related strategies.
Beneath the hype, it’s hard to know exactly who is doing what, since transparency ranges from NewLimit’s “garage-up” approach to complete secrecy. But from what I can tell, many are using high-throughput screens to rapidly test thousands of factor combinations. In a striking parallel, these modern scientists echo ancient alchemists, tossing random combinations of ingredients into their crucibles and relying more on empirical trial-and-error than fundamental understanding.
The modern crucible
At its core, biological screening involves two steps: creating diversity through perturbations, and measuring the resulting phenotypes. Remember classical genetics experiments, where scientists randomly mutated fruit fly genomes and searched for unusual outcomes, like bizarre wings or glowing eyes? Today, we've significantly leveled up on both fronts. For perturbations, tools like CRISPR enable precise targeting of individual genes, while for measuring phenotypes, technologies like single-cell RNA sequencing can link each perturbation to transcriptomic changes within individual cells. These innovations have transformed screening from crude, hit-or-miss experiments into powerful assays that precisely reveal how each molecular tweak shapes cell states.
Many reprogramming companies are following a similar playbook, but instead of using CRISPR-based perturbations, they're screening huge libraries of transcription factor combinations—essentially Yamanaka's approach on steroids. Their strategies for measuring the resulting phenotypes vary widely, reflecting a fundamental tradeoff between quantity and quality. At one extreme are ultra-high-throughput screens that evaluate billions of cells using simple readouts like proliferation or fluorescence markers. At the other extreme are methods like Perturb-seq or optical screens, which capture richer, higher-dimensional information, but at lower throughput.
Unlike traditional hypothesis-driven research, where scientists formulate specific ideas and design experiments to test them, screening approaches exemplify discovery biology. In discovery biology, the priority shifts from understanding how something works to simply finding what works—often at far greater scale, which can uncover unexpected biological mechanisms.
That said, screening approaches introduce their own set of challenges. Most perturbations produce no meaningful effect, and even apparent hits may reflect technical artifacts. Concerns like these help explain why biotech traditionally favors targeted, single-asset approaches, and why even industry leaders like Genentech and Recursion are still battling to prove that large-scale screening platforms can truly accelerate drug discovery. Despite these limitations, carefully designed screens with proper controls hold immense promise for uncovering new biology from single drugs or simple genetic tweaks.
Yet, controlling biological systems is rarely so simple. Humans have roughly 1,600 transcription factors, so identifying a therapeutic combination of just four creates over 270 billion possibilities, even before considering timing, dosage, or isoforms. Even with today’s advances in DNA sequencing and synthesis, we remain many orders of magnitude away from experimentally testing every combination.
Many companies are betting on artificial intelligence to navigate this vast combinatorial space, particularly through active learning or lab-in-the-loop strategies where models (or soon, AI agents) iteratively refine experiments. Typically, this involves first testing an initial, diverse set of combinations to collect data and train predictive models. These models then suggest new combinations where outcomes are uncertain, repeatedly iterating this cycle until they precisely capture the biological system's underlying rules. While this continuous refinement is appealing from an engineering perspective, I believe it overlooks a crucial limitation that sets the stage for the rest of this essay: RNA measurements alone aren't enough to fully decode cells.
The RNA world is not enough
Look, RNA is cool—some scientists even propose it as life's original building block. Like DNA, RNA is composed of nucleic acids, making it readily sequenceable. But unlike DNA, RNA expression varies substantially across cell types, making it a powerful readout of molecular states. Messenger RNA features distinctive poly-A tails, enabling efficient profiling of all ~20,000 genes in a single cell. These characteristics explain why today's most advanced single-cell screening technologies primarily measure RNA.
Yet measuring RNA alone has critical limitations. In Francis Crick’s famous “central dogma” of biology, RNA sits between DNA and proteins—neither the starting point nor the final outcome. Thus, even capturing all the RNA in a cell provides only a partial, noisy snapshot of cellular reality. As we'll discuss later, this inherent noisiness fundamentally limits the most cutting edge AI methods from accurately predicting how single cells respond to specific perturbations.
In some ways, relying solely on RNA to understand cell state is like interpreting a football game using only basic statistics. If you looked exclusively at the box score from the latest Super Bowl, you might conclude Patrick Mahomes played poorly because he passed for only 257 yards. But those numbers miss critical context—maybe his offensive line collapsed, maybe receivers dropped passes, or maybe he really did no-show. Recognizing these limitations, football analysts developed advanced metrics to evaluate each player's contributions on every play, even those who never touch the ball.

To truly understand reprogramming, we need a similar revolution: richer measurements revealing exactly how transcription factors work together to turn genes on and off, repairing cellular damage in the process. How exactly do the Yamanaka factors erase a cell’s previous identity? How does this process reset aging signatures captured by DNA methylation clocks? And how does this reset compare to the “ground zero” state established naturally during meiosis? The fundamental mechanisms of reprogramming are still waiting to be unlocked.
History offers a valuable lesson: the alchemists never succeeded in mastering matter because they lacked the tools to identify its true building blocks. Similarly, the next leap in cellular reprogramming won't arise simply by scaling RNA screens or applying more sophisticated AI. Instead, we must create new technologies to understand and harness the mechanisms cells use to rewrite their biological destiny.
From Gurdon to Yamanaka to today, the story of cellular alchemy is still unfolding.
Note: Despite these criticisms, I’m genuinely rooting for today's reprogramming companies. Many have chosen excellent initial targets: NewLimit is tackling T cell rejuvenation, and Retro is working on hematopoietic stem cells. Both are cell types that are comparatively straightforward to deliver therapeutically and address substantial medical needs. But addressing larger challenges, such as preventing brain aging or regenerating heart tissue, will ultimately depend on developing the tools described in the remainder of this essay.
II: Solving the epigenome
“Imagine that 30 years ago, a funder were working toward understanding and mitigating the fundamental causes of aging. Our intuition is that they would want a large share of their effort to go toward supporting very basic work on gene sequencing, microscopy, the areas of cell biology that have led to the field of epigenetics, and topics in cell differentiation that led to the discovery of stem cells – rather than work that might fall under the auspices of ‘aging research’ per se. We suspect something similar is still true today.”
– Open Philanthropy, Mechanisms of Aging
Under the hood
If you’re still here, I can only assume you care about how reprogramming actually works. Let’s dive into the nitty-gritty.
In mature cells, genes required for pluripotency are typically silent, marked as inactive by repressive histone marks and DNA methylation. When we introduce the Yamanaka factors, OCT4, SOX2, and KLF4 act as “pioneer factors,” opening tightly packed chromatin around these genes and recruiting cofactors for active transcription.
But the process doesn't stop there. The initial wave of activated genes includes additional transcription factors, which then target new genomic regions, turning on further pluripotency-associated genes while silencing those linked to the cell’s original identity. Beyond just altered activity levels, each region also acquires its own unique combination of chemical markers and spatial positioning within the nucleus. Collectively, these cascades reshape cellular identity.
At least, that's our current understanding. If this explanation seems vague, it’s partly for simplicity, but also because the relationships between these mechanisms remain surprisingly mysterious.
Many of these mechanisms—histone modifications, DNA methylation, chromatin states, transcription factor dynamics—were discovered independently, using different techniques, and thus remain fragmented into separate subfields. Yet it’s increasingly clear that their interactions lie at the very core of how a single genome specifies diverse cellular identities. How can we hope to fully understand reprogramming without studying these mechanisms as part of an integrated whole?
What I talk about when I talk about epigenomics
Every field needs a name. But what do you call the study of how a single genome gives rise to all the cell types in the human body, and how these mechanisms falter during aging and disease?
You might suggest development, but that traditionally describes how organs and tissues form early in life, with limited focus on the genome or what happens after maturity. Gene regulation feels too narrow, emphasizing the molecular ballet that fine-tunes individual genes rather than how these mechanisms collectively produce diverse cell identities. Genomics? Unfortunately, that term is already widely used—either narrowly, to describe studies of genetic variation, or broadly, as a catch-all for anything involving sequencing. Other terms like functional genomics, the 4D nucleome, and the regulome also miss the mark.
In this essay, I've decided to reclaim the term epigenomics.
Traditionally, epigenomics has been defined as "the study of chemical modifications that attach to DNA and alter gene function. This limited framing stems largely from debates surrounding its controversial cousin, epigenetics, a term burdened by persistent debates over mechanism and timescale.

Yet these debates miss the forest for the trees. Reducing epigenomics to a mere collection of chemical modifications completely overlooks the awe-inspiring mystery of how a single cell becomes an entire human brain. Epigenomics isn’t stamp collecting; it’s about decoding life's deepest secrets:
How does one genome produce the incredible variety of cells forming a complete organism?
How do these myriad cells know exactly what to do, at precisely the right place and time?
How does this intricate cellular symphony unravel with age, inevitably leading to disease?
Answering these fundamental questions requires a shift in perspective: we must see the epigenome not simply as a collection of chemical marks, but as the central processing unit of the cell.
Everything is computer
In computing, the CPU is often called the brain of the machine. It interprets user inputs, processes this information according to its programming, and generates precise outputs. Similarly, the epigenome acts as the central processing unit of the cell. It continuously integrates diverse external signals—chemical gradients, soluble growth factors, interactions with neighboring cells—and translates them into precise phenotypes, the distinct physical characteristics and behaviors that define each cell’s specialized role. This remarkable information-processing capability is what enables cells to act appropriately in their unique contexts.
Consider a stem cell. It senses cues from the embryonic environment instructing it to remain pluripotent, retaining the potential to become any type of cell. In contrast, a cardiomyocyte in the heart integrates electrical signals from neighboring cells, enabling precise, rhythmic contractions.

At this point, some might ask: Why emphasize the epigenome rather than other cellular components like RNA, proteins, or metabolites?
While other layers of regulation undoubtedly matter, it helps to reason from first principles. Biological differences between organisms generally arise from variations in DNA sequence, but all cells within your body share the same genome. Thus, the epigenome serves as the primary driver of cellular variation within an organism. This is clearly evident in cell atlases, which consistently reveal dramatic differences in RNA expression between an organism's diverse cell types. These distinct patterns are largely mediated by underlying differences in the epigenome, which translates diverse environmental signals into precise gene expression programs.
Does this imply that epigenomic mechanisms alone explain all cellular complexity? Certainly not. Post-transcriptional regulation, signal transduction, metabolism, and myriad other processes collectively enrich and refine cellular function. Yet, the epigenome provides the foundational layer for cellular diversity, so focusing on this foundational level likely gives us the most leverage to rewrite cell identity.
The epigenome's remarkable ability to integrate and respond to diverse signals makes it a textbook example of a complex system, a system whose interacting components collectively produce behaviors greater than the sum of their individual parts. To study complex systems, researchers in systems biology commonly employ a “perturb-measure-analyze” framework: first, perturb individual components; then measure how these perturbations affect system behavior; and finally analyze the results to uncover causal relationships.

While some efforts have attempted to apply this framework to the epigenome, most existing gene regulatory networks neglect environmental inputs and phenotypic outcomes. To fully understand the epigenome as an information-processing system, we must develop new technologies to perturb, measure, and analyze the system as an integrated whole:
How can we perturb the epigenome with the necessary precision and throughput to systematically explore cellular states?
How do we simultaneously measure environmental signals, epigenetic states, and phenotypic responses within individual cells?
How do we analyze these complex data sets to accurately predict cellular outcomes?
To illustrate how the perturb-measure-analyze framework can inspire new technologies, let's briefly step outside of epigenomics and consider neuroscientist Ed Boyden, who applies a similar approach to tackle one of biology's greatest challenges—solving the brain.
Ed Boyden’s framework for “solving the brain”
The complexity of the epigenome is staggering. Thousands of proteins and regulatory elements dynamically interact to control gene expression, enabling cells to respond to their environment and coordinate intricate behaviors. In some ways, this resembles the organizational complexity of the brain, whose billions of interconnected neurons similarly integrate diverse signals to produce thought, emotion, and behavior. Given these parallels, frameworks developed to decode brain complexity might offer powerful insights for understanding the epigenome.
On the After On podcast, MIT neurobiologist Ed Boyden describes his lab’s ambitious goal as "solving the brain," which he summarizes as follows:
"My dream would be to have the right kind of biological data, structural and dynamic, so I could simulate in a computer, in a biophysically accurate, yet human understandable way, how a brain circuit implements a decision, or an emotion, or some other complex function that characterizes, in the beginning, the processes of small brains, like animal brains, but eventually the human brain."
Recognizing early on that the brain was a complex system allowed Boyden to identify three essential classes of technologies:
Manipulation technologies to control cellular activity
Temporal technologies to observe cellular dynamics
Spatial technologies to map molecules within cells, and cells within tissues
Articulating these technological goals enabled Boyden's lab to pioneer groundbreaking tools in each area: optogenetics enables precise manipulation of neurons using light, voltage indicators record electrical activity, and expansion microscopy reveals molecular wiring by physically enlarging samples. But the true power of these innovations comes from integrating them—researchers can manipulate neurons, monitor their activity during behaviors, and map their wiring afterward, creating a complete framework for understanding causality in the brain.
Boyden himself implicitly suggests a fourth essential element in his vision: computational models. Integrating manipulation, temporal, and spatial data into models could allow his team to accurately simulate brain function and generate precise predictions. Accurate predictive models demonstrate genuine understanding, revealing how to reverse-engineer specific behaviors, and even generating unexpected new hypotheses to test experimentally.
Boyden’s ultimate goal of stimulating, observing, and mapping brain circuits to decode complex behaviors provided his lab with an ambitious vision that guided innovation across these technological areas. What might a similarly ambitious vision look like for the epigenome?
What it means to “solve the epigenome”
For me, "solving the epigenome" means building a generalizable framework to create any healthy cell type in the human body.
Imagine optimized “recipes” that reliably generate specific cell types from any starting point, even diseased or aged cells. This capability could redefine what's possible in what we consider medical care. Doctors could rejuvenate immune cells in elderly patients, regenerate damaged heart tissue after a heart attack, or replace muscle cells lost during aging. Crucially, just as a good cooking recipe includes not only ingredients but also precise measurements, step times, and prep work, true reprogramming may require tuning dosage, timing, and initial cellular conditions.
Realizing this vision requires moving beyond the trial-and-error methods currently employed. Instead, much like Boyden’s systematic approach to decoding the brain, we need a structured framework to understand the epigenome as a sophisticated information-processing system. Specifically, we must develop three complementary classes of epigenomic technologies:
Epigenomic manipulation technologies will let us explore the full landscape of possible cell states. By engineering transcription factors, we'll reliably guide cells toward desired phenotypes.
Epigenomic measurement technologies will let us observe how our manipulations affect cells across all levels. With multi-modal spatial methods, we'll simultaneously capture environment, epigenome, and phenotype, directly linking molecular states to observable behaviors.
Epigenomic modeling technologies will convert this wealth of data into accurate predictions. By integrating multi-modal data from trillions of cells and manipulations, we'll reliably determine the optimal recipe needed to produce cells with specific functions.
You’ll notice I’ve slightly adjusted the original "perturb-measure-analyze" terminology here, replacing perturb with manipulate, and analysis with model. Beyond the nice alliteration, these shifts carry intentional meaning. Perturbation often implies disruption or breaking something, whereas manipulation suggests precise, intentional control. Similarly, analysis can imply passively examining existing data, while modeling emphasizes actively building predictive frameworks that generate testable hypotheses.
Together, these technologies create a powerful feedback loop: manipulation generates diverse cellular states through controlled changes; measurement captures the molecular and functional consequences of these changes in their native context; and modeling integrates these results into predictions that guide subsequent manipulations. Repeatedly cycling through this "manipulate-measure-model" loop will steadily refine our cellular recipes, ultimately enabling safer and more effective therapeutic strategies.
In the interlude that follows, I'll explore each of these technological classes in greater depth, discussing current challenges and highlighting promising paths forward.
Technical interlude: the epigenomic toolkit
Epigenomic manipulation
The ultimate goal of cellular alchemy is to create cells with specific phenotypes. If the epigenome acts as the cell's central processor, how can we effectively manipulate it to achieve this?
An “outside-in” approach involves modulating external signals received by cells, thereby altering their epigenetic states and ultimately shaping their phenotypes. John Gurdon demonstrated this by transplanting the nucleus of a mature cell into a frog egg, proving that environmental cues alone could reset cellular identity. Alternatively, an “inside-out” approach directly rewrites the epigenome’s internal state to influence phenotype. Shinya Yamanaka showed this was possible by introducing just four transcription factors into mature cells, reverting them to pluripotency without changing external signals.
While both approaches have merit, the outside-in strategy faces substantial hurdles. First, the sheer number of environmental signals and their possible spatiotemporal combinations is virtually infinite. To recapitulate a developmental pathway, how precisely must we replicate physiological conditions? This complexity helps explain why engineering artificial organs remains so challenging. Second, these signals typically flow in one direction, so simply removing an external cue rarely reverses its downstream effects. Finally, some cell conversions—such as reverting aged cells to a youthful state—may not be achievable through environmental signals alone.
In contrast, the inside-out approach offers far greater precision and programmability. Unlike the near-infinite complexity of environmental signals, the epigenome has a finite structure: about 20,000 genes and their regulatory regions, each with a specific nucleic acid sequence. Using genome engineering tools, we can target factors to these genes to turn them on and off. Moreover, to achieve complex outcomes, multiple factors can be introduced simultaneously. But how much of the epigenome do we actually need to change to reprogram cell identity?
We are in a golden age of genome engineering, with new DNA-editing tools constantly emerging. Yet, engineering the epigenome poses fundamentally different challenges—rather than simply correcting single genes, reshaping cellular identity requires activating and silencing large gene networks. Achieving this balance between precision and scale remains difficult, with current approaches typically occupying one of two extremes.
On one end, targeted methods such as CRISPRa and CRISPRi precisely modulate gene expression by recruiting functional protein domains to specific genomic regions. Although highly precise, these approaches are difficult to scale beyond a handful of genes. At the other extreme, epigenetic drugs broadly alter nearly every instance of a given modification throughout the genome. While effective against certain cancers, this approach lacks subtlety. To reliably reprogram cellular identity, we need techniques that can precisely regulate sets of genes in a coordinated manner.
Fortunately, we don't have to build this machinery from scratch, as nature already provides a built-in solution. As previously discussed, transcription factors are natural proteins that have evolved to orchestrate developmental gene programs during cell differentiation.
In the 1950s, Conrad Waddington famously illustrated differentiation as a marble rolling down a landscape, with valleys representing stable cell types. Beneath this landscape, he drew hidden “guy-wires” dynamically shaping the landscape to pull cells toward different developmental outcomes. Waddington's ideas were remarkably prescient, appearing decades before the discovery of transcription factors.

Even today, Waddington's landscape reveals two key insights about differentiation. First, individual transcription factors don't dictate cell fate by themselves, but instead subtly nudge cells toward particular outcomes. These subtle nudges combine probabilistically, generating the diverse spectrum of cellular identities observed in the body, but complicating our efforts to deterministically produce specific cell types. Second, cells naturally follow a limited set of developmental paths. But what if we could design new routes? To more reliably produce existing cell types or create entirely new ones, we must learn to hack transcription factors, borrowing principles from synthetic biology to harness nature’s built-in controllers for our own purposes.
Despite rapid progress in protein engineering, transcription factors present unique challenges due to their multifunctional nature. Transcription factors typically contain three components: intrinsically disordered domains that broadly localize them within the genome, DNA-binding domains that precisely recognize specific DNA motifs, and effector domains that activate or repress gene expression. Engineering transcription factors is challenging because modifications in one region can inadvertently impact another. For example, activation domains frequently overlap with disordered regions, so enhancing activation strength might unintentionally alter genomic localization. To overcome these complexities, we'll pursue two complementary synthetic biology strategies: top-down and bottom-up engineering.
The top-down approach involves making targeted modifications to existing transcription factors, a practical strategy for enhancing existing reprogramming methods. For instance, engineering variants of the Yamanaka factors that more effectively bind tightly closed chromatin could substantially boost reprogramming efficiency. However, due to their intrinsically disordered regions (which standard protein structure tools struggle to model), transcription factors may require domain-specific machine learning methods to predict activation strength or to quantify patterned charge blocks of amino acids. Along these lines, Retro reportedly developed a model that predicts SOX2 and KLF4 variants with enhanced reprogramming capabilities, although their methods and data have not yet been disclosed.
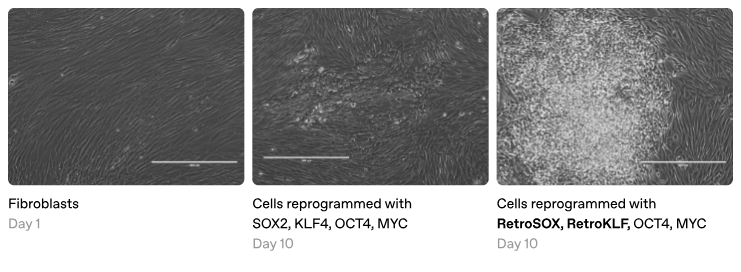
The bottom-up approach involves designing new transcription factors by combining functional domains from natural proteins. Although many initial combinations may fail, systematic experimentation could yield a modular library of “biobricks” with well-characterized effects, enabling assembly of synthetic factors that can produce any desired cell type. For example, we might engineer hybrid cardiomyocytes that combine the mature functionality of adult heart cells with the regenerative potential of neonatal cells. This could be accomplished by designing factors that simultaneously activate genes associated with mature cardiac function and prime genes involved in proliferation. Far from science fiction, the Satpathy lab recently demonstrated modular engineering of AP1 transcription factors, and Tune Therapeutics appears to be pursuing a similar approach.

Together, these top-down and bottom-up strategies could enable us to precisely manipulate the epigenome at will. But how can we understand the consequences of our interventions?
Epigenomic measurement
To fully understand how the epigenome processes information, we need technologies that measure the entire system simultaneously: environmental inputs, epigenetic states, and phenotypic outputs. What approaches do we currently have?
The microscope opened our eyes to the cellular world. Since Robert Hooke’s first drawings of cells in 1665, imaging has allowed us to classify cells based on physical attributes like size, shape, and position. Modern microscopes now visualize tissues in three dimensions, preserving crucial environmental context, while live imaging captures cell behaviors as they unfold in real time. Imaging remains the clinical gold standard for diagnosing conditions ranging from cancer to blood disorders.
DNA sequencing enabled us to read biology’s molecular language. Since Frederick Sanger’s pioneering work in 1977, sequencing technologies have evolved dramatically, now revealing not only genetic information but also how cellular states vary across tissues, diseases, and aging. Modern methods routinely profile transcriptomes and epigenetic states at the resolution of single cells, enabling large-scale cellular atlases of all the tissues and organs in the human body.
But can we effectively capture the environment and phenotype with imaging, while separately relying on sequencing to reveal epigenomic states? Not quite. The real power of multi-modal methods, which measure multiple biological aspects simultaneously in the same cells, is their ability to establish direct connections.
For instance, pathologists frequently diagnose diseases solely based on cellular appearance, but rarely connect these visual features directly to molecular signatures revealed by sequencing. Similarly, aging researchers quantify biological age using DNA methylation clocks but struggle to directly link these epigenetic changes to observable phenotypic markers of aging. Truly understanding these relationships demands new multi-modal technologies that simultaneously measure environment, epigenome, and phenotypic for individual cells.
So how do we connect the rich spatial detail we see under the microscope to the multi-dimensional molecular states revealed by sequencing? Traditional sequencing methods involve grinding up tissues, destroying positional information, while microscopy preserves spatial context but typically measures only a handful of molecular targets. Enter spatial technologies.
Spatial technologies bridge imaging and sequencing through a surprisingly simple insight. In standard Illumina sequencing, DNA is extracted from cells, immobilized on a patterned flow cell, and imaged repeatedly as fluorescent bases are added one by one. In other words, a DNA sequencer is essentially just a specialized microscope in disguise! Spatial technologies cleverly leverage this concept, skipping the DNA extraction and performing sequencing reactions directly within intact tissues to preserve their natural spatial architecture.
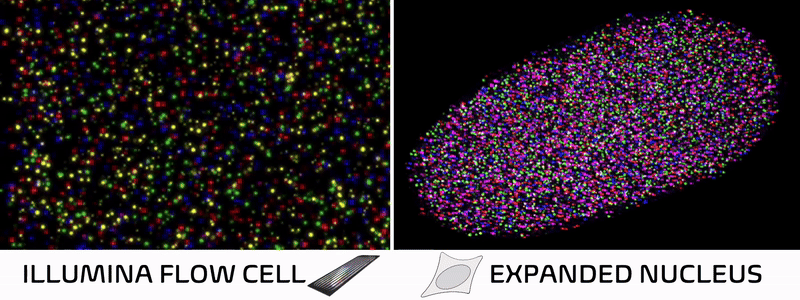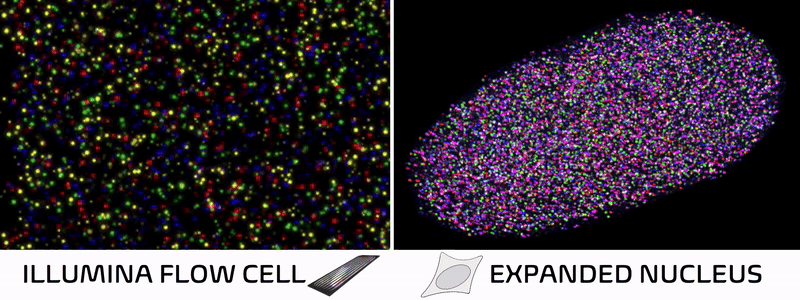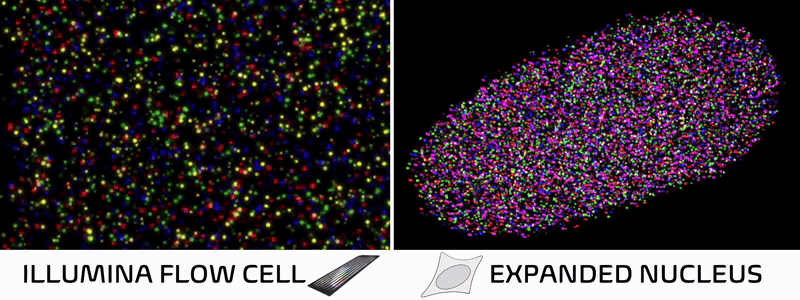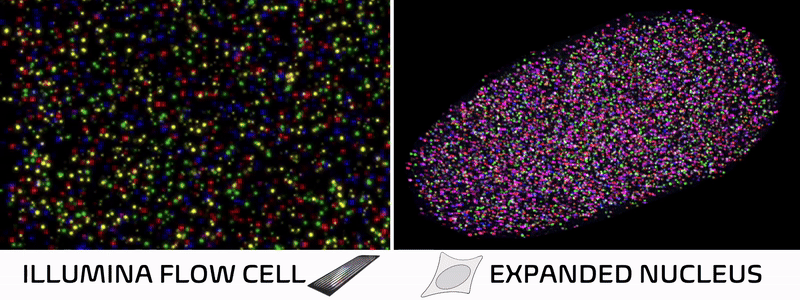
Over the past decade, spatial technologies have rapidly evolved, transitioning from niche academic methods into ubiquitous commercial platforms. Most of these approaches map the localization of RNA molecules in a tissue, allowing researchers to connect a cell’s spatial neighborhood to its transcriptional state. But while some methods add protein localization or cell morphology, nearly all overlook the foundational layer of cellular identity—the epigenome.
Why has the epigenome been left behind? Measuring it is uniquely challenging, requiring techniques to simultaneously read the genome’s 3 billion bases, detect diverse biochemical marks, and map interactions at nanoscale within the nucleus.
It just so happens my own research tackles exactly these challenges! We recently developed Expansion in situ genome sequencing (ExIGS), a method for sequencing DNA directly within physically expanded nuclei to directly connect nuclear phenotypes and epigenetic states.

To demonstrate this approach, we studied progeria, a premature aging disease characterized by defects in the nuclear lamina, a critical structural component of the nucleus. With ExIGS, we directly demonstrated for the first time how structural defects in nuclear shape disrupt the structure of chromosomes, bridging a classic disease phenotype with epigenetic measurements.

ExIGS brings us closer than ever to comprehensive measurement of environment, epigenome, and phenotype. But what would the perfect measurement instrument look like?
In Spatial technologies of the future (a deeper dive into spatial measurements), I introduced a thought experiment called the Magic Microscope. The premise was simple: setting aside today's technical limits, what would the perfect measurement instrument of the future look like?
Though intentionally speculative, this exercise reveals technologies that offer promising long-term paths toward these goals. In that essay, I identified three core capabilities such an ideal device would possess: (1) identifying every molecule, (2) mapping each molecule with perfect spatial resolution, and (3) continuously tracking these molecular dynamics over time. Spatial technologies offer a long, but promising path toward these ambitious goals.
For molecular resolution, spatial methods keep biological samples intact, letting us measure DNA, RNA, proteins, and epigenetic marks all together in their natural environment.
For spatial resolution, expansion microscopy methods have rapidly improved from ~4x to ~20x magnification, offering a clear path to true molecular-scale imaging.
Capturing temporal dynamics remains the most challenging, since sequencing methods are inherently destructive, providing only snapshots in time. However, emerging workflows now combine live-cell imaging with subsequent spatial readouts, and advances in ultrasound imaging, RNA export, and label-free microscopy promise exciting new ways to track biology as it unfolds.
Lastly, scale underpins everything we've discussed. A Magic Microscope measuring just a handful of cells won't be enough—we need methods that can analyze billions, or even trillions of cells to truly decode how environment, epigenome, and phenotype interact. Only at such massive scales can we fully harness the transcription factor engineering strategies described earlier.
Achieving this scale will produce enormous datasets, demanding new computational methods that integrate diverse manipulations and measurements to uncover the fundamental rules guiding cellular identity and function.
Epigenomic modeling
AI will solve biology for us.
Just kidding! Artificial intelligence is undoubtedly becoming more powerful, but even its most enthusiastic advocates acknowledge that careful data selection and model design remain essential, particularly in biology. I'm not an expert in AI architectures, so I'll focus mainly on the data side.
Stepping back from cell reprogramming for a moment, some biologists have recently become excited about the concept of a "virtual cell." According to the Virtual Cell white paper:
"Advances in AI and omics offer groundbreaking opportunities to create an AI virtual cell (AIVC), a multi-scale, multi-modal large-neural-network-based model that can represent and simulate the behavior of molecules, cells, and tissues across diverse states."
Interestingly, this isn't far from what we've been discussing in the context of the epigenome. Many elements overlap, including the use of perturbations and multi-modal measurements to build computational models, but one crucial piece is conspicuously missing.

You've probably guessed the glaring omission: the epigenome. While some dismiss efforts like these for overhyping AI or inventing fancy new terms, my critique is simpler: You can't build a virtual cell without understanding the epigenome.
But let’s play devil’s advocate: perhaps we can build a virtual cell without fully understanding its inner workings.
In the AI community, there's ongoing debate about whether scale alone is all you need. Some argue that recent breakthroughs in large language models stem not from smarter architectures or higher-quality data, but simply from building bigger and bigger models. Inspired by the success of models like ChatGPT, researchers have begun applying similar approaches to single-cell biology. The latest wave includes foundational models, which are trained on enormous unannotated datasets and designed to perform well across diverse biological problems.
Much to the delight of AI skeptics, recent benchmarking studies have thrown cold water on these foundational models. These studies evaluated models' abilities to predict transcriptional responses to perturbations and found many barely outperform simple linear regression. Ouch. The main issue is that most perturbations have minimal effects, so models can achieve deceptively strong performance simply by predicting average responses, rather than capturing meaningful biology. This is slightly concerning, given that similar AI models are central to the FDA’s strategy for replacing animal models in drug testing.
There is considerable debate over how to improve model performance, with three main possibilities: refining model architectures, scaling up datasets, or changing the type of data collected. Computational biologists are actively exploring new model architectures, and large-scale initiatives such as the Arc Virtual Cell Atlas are explicitly testing the scalability hypothesis by mapping responses to over 1,100 drugs across 50 cancer models and 100 million cells. Xaira Therapeutics is also reportedly investing part of its $1 billion(!) "war chest" toward similar efforts. However, my intuition is that truly accurate cell modeling will require fundamentally new technologies capable of directly measuring how cells process information. Fortunately, that's a problem we can solve.
Counterintuitively, nothing illustrates the importance of having the right type of data better than AI's most celebrated success in biology: AlphaFold.
Although AlphaFold’s neural networks builders win most of the accolades, their success depended on decades of foundational research. For AlphaFold to succeed, DeepMind needed the PDB (Protein Data Bank), a massive public repository of solved protein structures that provided essential training data. And for the PDB to even exist, scientists first had to develop techniques like cryo-EM (cryo-electron microscopy) to determine protein structures at atomic resolution.
Cryo-EM captures thousands of two-dimensional images of molecules from multiple angles, computationally reconstructing them into a single 3D structure. Because of this reliance on static snapshots, AlphaFold still struggles to accurately model proteins that dynamically shift or move. In other words, our ability to model biology remains fundamentally constrained by the limits of our measurement technologies.

But even proteins that shift between multiple conformations pale in comparison to the complexity of the epigenome. With its three billion base pairs and numerous regulatory layers, the epigenome integrates diverse environmental signals to generate all cell types in the human body. So what's the solution?
Earlier in this essay, we discussed how transcription factor-based manipulation allows us to navigate the full landscape of epigenetic states. We also explored how spatial technologies offer ways to measure multiple biological features simultaneously, at higher resolution and more relevant timepoints. Integrated and scaled appropriately, these approaches could become the equivalent of cryo-EM for the epigenome.
As these measurement and manipulation tools mature, we'll be able to develop computational models explicitly guided by the concept of the epigenome as a cellular processor. These models could predict cellular outcomes based on specific environmental signals, current epigenetic states, and targeted transcription factor manipulations. They could also be applied in reverse, nominating precise epigenetic and environmental interventions needed to engineer desired cell phenotypes, and bringing us closer to realizing a reliable recipe for every healthy cell type in the human body.
AI is rapidly advancing, and the future will undoubtedly involve the lab-in-the-loop systems: computational models that design experiments, execute them, and continually refine their predictions based on the results. Each iteration will improve our ability to engineer precise cell types, bringing safe and effective reprogramming therapies within reach. But to fully realize this vision, we must first harness a bit of our own ingenuity to build the enabling epigenomic technologies.
III: Rewriting the future
“Because biographies of famous scientists tend to edit out their mistakes, we underestimate the degree of risk they were willing to take. And because anything a famous scientist did that wasn't a mistake has probably now become the conventional wisdom, those choices don't seem risky either.
Biographies of Newton, for example, understandably focus more on physics than alchemy or theology. The impression we get is that his unerring judgment led him straight to truths no one else had noticed. How to explain all the time he spent on alchemy and theology? Well, smart people are often kind of crazy.
But maybe there is a simpler explanation. Maybe the smartness and the craziness were not as separate as we think. Physics seems to us a promising thing to work on, and alchemy and theology obvious wastes of time. But that's because we know how things turned out. In Newton's day the three problems seemed roughly equally promising. No one knew yet what the payoff would be for inventing what we now call physics; if they had, more people would have been working on it. And alchemy and theology were still then in the category Marc Andreessen would describe as ‘huge, if true.’
Newton made three bets. One of them worked. But they were all risky.”
– Paul Graham, The Risk of Discovery
Why we’re polarized (on aging)
Cellular reprogramming technologies offer revolutionary potential to improve human health by addressing aging and many diseases, yet few scientific fields generate such polarized reactions.
On one extreme are enthusiasts, who scream from the rooftops about immortality. This zeal has fostered some questionable enterprises: professors pushing dubious supplements, “longevity states” with their own form of currency, and yes, father-son blood transfusions. Such pseudoscience inevitably invites justified skepticism.
On the other end are skeptics who dismiss anti-aging or reprogramming research entirely, wary of flashy promises and viewing lifespan extension as fundamentally unnatural. While skepticism is understandable, rejecting the entire field risks losing valuable science alongside the hype.
Today, the loudest and most opinionated voices dominate discussions, fueling polarization and drowning out nuance. Yet it's safe to say that the truth lies somewhere in between: reprogramming offers genuine scientific promise, but realizing its potential demands precise long-term visions, sustained investment in fundamental technologies, and practical short-term strategies, in that order.
To help guide the conversation back toward this productive middle ground, I've written two sections designed to meet you wherever your current beliefs fall:
If you're skeptical of claims about immortality or that biology can be "solved" like software, the next section acknowledges your concerns, emphasizing that tangible progress requires technologies built to handle biology's inherent complexity.
If you lean toward enthusiasm, the subsequent section respects your excitement but emphasizes the need for careful evaluation of strategies that can drive truly transformative progress and sustained investment in basic technology development.
After exploring both viewpoints, we'll chart a shared path forward by discussing how cellular reprogramming technologies might realistically transform society in both the near and distant future.
To the skeptic
Let's be honest: some ideas in this essay probably come across as classic tech-bro naïvety—the notion that biology is just buggy software awaiting “real” programmers. Lately, we've been bombarded with bold promises about solving drug discovery or aging through sheer computational muscle, as if biologists have never heard of quantitative methods. If that sort of hubris gets your blood boiling, I'm with you.
Biology is inherently messy. Anyone who’s touched a pipette knows every cell type has quirks, every measurement contains bias, and every rule has exceptions. Evolved systems are a lot more complex than human designed ones. Literally everything is context-dependent. There’s a long history of physicists, mathematicians, and computer scientists being humbled by biology’s complexity.
Yet some have found success by embracing this complexity. Physicist Erwin Schrödinger helped launch molecular biology by posing fundamental quantitative questions about life itself. Mathematician Eric Lander played a pivotal role in sequencing the human genome, transforming biology into a data-driven science. Critically, neither succeeded by imposing simplicity—instead, they respected biology’s inherent complexity, patiently building rigorous, quantitative frameworks around it.
To be fair, the new wave of quantitative thinkers offers a slightly different argument: they acknowledge biology’s complexity but suggest artificial intelligence will simply handle it for us. No need to filter, no need to annotate. But as I argued earlier, this overlooks the biases and limitations inherent in our methods. There's no guarantee the fundamental answers about life are neatly hidden within the types of data we've already collecting. Meaningful progress will still require deliberately building technologies with biological complexity in mind.
And technology development is only the beginning. Real-world implementation demands experts in therapeutic delivery, specialists in tissue-specific biology, entrepreneurs developing sound business models, and clinical teams rigorously validating safety and efficacy. Moving from basic biology to healthcare is exceptionally difficult—I'm certainly not claiming otherwise. Whether these efforts ultimately succeed remains uncertain, but their potential to profoundly reshape human health makes them worthy of pursuit despite the challenges.
I'm not saying don't be skeptical. Especially in the aging field, we urgently need experts who will call bullshit—not just based on credentials, but on the strength of ideas and evidence. But don't dismiss ideas just because they're ambitious. Small steps toward breakthroughs often start with bold ideas—ideas that deserve people willing to fairly evaluate their potential. Or, as Anton Ego puts it beautifully in Ratatouille:
"But there are times when a critic truly risks something, and that is in the discovery and defense of the new. The world is often unkind to new talent, new creations. The new needs friends."
[If your concerns center more around the societal implications or discomfort with the idea of extending lifespan, we’ll address those directly in the "Cellular abundance" section.]
To the enthusiast
There's something thrilling about feeling privy to a secret that could redefine life as we know it. In this case, that we're on the cusp of dramatically extending human lifespan, and you might be among the first to benefit. Yet this excitement can sometimes lead to overenthusiasm about claims of imminent breakthroughs.
Consider longevity escape velocity, the idea that technological progress will soon extend lifespans faster than we age. Yet its acolytes often overlook a crucial point: technologies don't just magically advance—they require us to imagine and build the future.
The uncomfortable truth is there are no “adults” in the room who have the entire future mapped out, only researchers doing their best to develop long-term visions despite academic publishing pressures and short industry timelines. Unfortunately, these constraints often push us toward quick results rather than deeper understanding. Sure, testing compounds like rapamycin seems like low-hanging fruit, but longer-term breakthroughs will require understanding how interventions affect cells mechanistically. Standardizing biomarkers of aging is valuable, but uncovering what actually drives those biomarkers may be even more essential.
In many ways, the ideas presented here are a spiritual successor to Jean Hébert's Replacing Aging—one of the few genuinely long-term visions in the field, and a book that deeply influenced my thinking. Hébert argues that truly rejuvenating the body, rather than merely slowing aging, requires replacing its damaged parts. But growing entire functional organs faces enormous biological hurdles, without clear pathways for rapid progress. Even if these challenges could be solved, routinely transplanting organs into otherwise healthy people would carry profound risks and raise significant ethical questions. Moreover, many essential cell types don't neatly reside within discrete organs. Building on Hébert's vision, the approach outlined here shifts the unit of replacement from organs to cells—a more practical strategy, given our clearer vision for generating healthy cell types, and our better understanding of how to deliver gene and cell therapies.
I’d also be remiss not to mention David Sinclair’s Information Theory of Aging, which adapts Claude Shannon’s ideas to the genome and epigenome. While Sinclair and I share many similar views, I find it clearer to think of the epigenome as a cellular processor, rather than viewing the genome as merely an “observer” or a “backup copy” of information, especially when it comes to creating diverse cell states. But we share a keen interest in understanding how epigenetic precision deteriorates with age, and how reprogramming might restore these mechanisms.
I'm not saying that ambition and long-term thinking alone can solve aging. The field is overcrowded with speculative theories lacking clear evidence. In contrast, cellular reprogramming isn't just speculative—it has concrete, demonstrated proof-of-concept in Yamanaka's experiment and in the stem cell therapies performed worldwide every day.
That said, it’s likely that cellular reprogramming won’t fully address all hallmarks of aging. For instance, one reason Jean Hébert favors organ replacement over cell rejuvenation is that the latter may not address lipofuscin aggregates and extracellular damage. Identifying such limitations is crucial, but these gaps shouldn’t be used prematurely to dismiss promising approaches.
Instead, meaningful progress will require a diversity of ambitious, long-term visions grounded in fundamental biological principles and supported by tangible evidence. Even if you're not convinced by the vision I've presented, I challenge you to clearly articulate your own approach guided by these same principles.
Cellular abundance
Wherever you stand on anti-aging efforts, the one thing we can all agree on is that health matters. Health underpins nearly everything—our work, our relationships, our capacity for joy. When serious health challenges arise, whether for ourselves or our loved ones, other concerns fade into insignificance. And if you've been fortunate enough to avoid such challenges so far, you inevitably will. That’s the inescapable nature of life.
Given this reality, what matters most is creating more health.
In recent months, abundance has emerged as a compelling framework for tackling societal problems. Many current issues—housing, transportation, energy—are fundamentally problems of scarcity. Abundance offers a clear response: remove artificial or outdated barriers to create more of what we value. Right now, medicine largely waits until we’re sick before taking action. But what if we created more health, proactively protecting and renewing it across our entire lives?
This idea isn’t exactly novel. Consider sunscreen, cardio, and vaccines. At first glance these seem unrelated, yet all three proactively protect health: sunscreen shields us from harmful UV rays, cardio strengthens our hearts, and vaccines guard us against dangerous infections, despite what Big Brother might say.
The line between preventive measures and therapies is beginning to blur. GLP-1 receptor agonists (e.g. Ozempic) were initially developed to treat diabetes, but researchers quickly discovered their powerful preventive effects on obesity by influencing appetite and metabolism. Now they're even being explored to address conditions like addiction, demonstrating how therapies can improve quality of life beyond conventional definitions of disease.
Cellular reprogramming will likely follow a similar path. Early therapies will target conditions we currently struggle to treat effectively, such as muscular dystrophy, osteoporosis, and Parkinson’s disease. Once proven safe, these treatments could become broadly accessible, proactively addressing the physical and cognitive declines associated with aging. You probably won’t see dramatic changes overnight, but over time you could experience stronger bones, sharper memory, and perhaps even quicker recovery from a night of drinking.
If the idea of "anti-aging" still feels uncomfortable, consider thinking of these therapies simply as the next generation of cell and gene therapies, designed to keep us healthier for longer. Feng Zhang frames this as “restoring cellular homeostasis,” whereas Doug Melton calls it harnessing “maximally adaptive behavior.” Perhaps simplest is to think of it as creating more health.
Realizing this vision certainly won't be easy. Beyond developing technologies to harness the epigenome, we'll need to address challenges like effective delivery, managing immune responses, and ensuring long-term safety. But the hurdles aren’t only technical—they're societal too. We'll need thoughtful conversations about how to ensure these healthier lives are accessible to everyone, not just the privileged few. We'll also need to actively combat pseudoscience that exploits these ideas and rebuild public trust in the medical establishment.
If we're successful, our world might start to look different. People could remain dynamic and productive well into their 60s, 70s, or beyond. Extended fertility could offer greater freedom to have children later, reducing difficult tradeoffs between career and family. LeBron, who reportedly already uses stem cell therapies, might still play basketball at 60. Eventually, we’ll likely need to rethink how society is structured—though AI might push us there first anyway.
But here's the thing: unlike digital technologies, advances in health rarely come with hidden downsides. No one regrets reducing cancer mortality or curbing infectious disease (okay, maybe that one guy does). This makes the goal straightforward: abundant health for everyone. Healthier populations mean happier, more fulfilling lives. And once we've established this foundation, we can responsibly pursue even more ambitious possibilities.
The wings of tomorrow
The rise of CRISPR has given us the tools to rewrite life's blueprint. While we're still debating how best to responsibly harness this extraordinary capability, society is gradually warming up to the idea of taking control of our biological destiny. As transformative as this acceptance might be, it's only the beginning. Gene editing can let us fix genetic errors and fine-tune our biology, but technologies that harness the epigenome could unlock biological superpowers.
One of gene editing’s greatest challenges is pleiotropy—the phenomenon where a single genetic change can have drastically different effects depending on context. The classic example is sickle cell anemia. People inheriting two copies of a specific mutation produce abnormally shaped “sickle” red blood cells, leading to severe anemia, organ damage, and chronic pain. Yet individuals with just one copy of the mutation experience milder symptoms as well as a surprising benefit: resistance to malaria, a significant advantage in regions where this disease is widespread.
This sensitivity to biological context poses a critical challenge to our boldest ambitions for gene editing. For instance, lengthening telomeres might sound like a promising strategy to slow aging, but evidence suggests it increases cancer risk. Similarly, adding extra tumor-suppressor genes—like the 20 copies of p53 found in elephants—seems beneficial, but we have no idea how these edits might negatively impact the hundreds of distinct cell types across our bodies. But what if we had epigenomic technologies precise enough to safely activate these genes only in the right cells, at exactly the right times?
As a thought experiment to showcase the power of epigenetic control, let's explore a purposely outlandish scenario: How could we engineer humans with functional wings? Just as 20 CRISPR edits don't make a true direwolf, no clever combination of genetic edits alone would let us soar through the skies. Sure, you could pinpoint the genomic regions birds use to grow wings, but simply pasting these sequences into the human genome would likely wreak biological havoc, disrupting countless essential processes.
But what if we inserted these wing-forming genes into the human genome, carefully programming them to remain silent until needed? At precisely chosen locations along the spine, triggered by a specific combination of signals, these dormant programs could spring to life. The activated cells would then initiate an entirely new developmental sequence, assembling functional wings from cell types never before seen in humans.
Yes, the idea of humans flying is a bit preposterous—but that's exactly the point. Precise control over the epigenome could unlock the astounding diversity of life itself. Aided by future iterations of generative DNA models like Evo 2, we could engineer specific cells to borrow extraordinary abilities from other species: regenerating limbs like an axolotl, resisting radiation like a tardigrade, or even photosynthesizing like a plant.
These possibilities may sound like science fiction, but less than a century ago, we didn't even know DNA carried genetic information. Today we can read, write, and edit it at will. Harnessing the epigenome—the true source code for building a human—is biology’s next great frontier. By thoughtfully developing these tools, we'll go beyond merely fixing what's broken; we'll gain the ability to write bold new chapters in humanity’s story.
Coda
“born too late to get a two Western blot Nature paper, born too early to be a science TikTokker, born just in time to start a postdoc during a global pandemic and look for faculty positions during a historic hiring freeze”
Sorry, the old academia can’t come to the phone right now. Why? Oh, because it’s dead.
When I started writing this essay in January, I intended it as a guiding vision for my future lab. The technologies I outlined for measuring, manipulating, and modeling the epigenome were to form the core of my research program for decades to come. Today, that future feels increasingly uncertain.
Even under ideal conditions, becoming a biomedical professor in the U.S. is arduous. Starting graduate school immediately after college typically involves ~4–8 years to complete a PhD, followed by another ~2–6 years as a postdoc—roughly a decade of training before even applying for faculty positions. This extended apprenticeship helps explain why the average age at which researchers receive their first independent NIH funding is now over 40, and why the share of funding awarded to young scientists has fallen precipitously.

But even more jarring than the long timeline is the abrupt shift in responsibilities and vision. As a graduate student or postdoc, your focus is purely research. When you become a principal investigator, you suddenly transition from scientist to small business manager—mentoring students, teaching, managing budgets, navigating bureaucracy, and recruiting talent. Amidst this daily whirlwind, you're also expected to execute a bold long-term vision—one that could transform your field and perhaps even the world.
Despite these nearly impossible expectations, competition for faculty positions is brutal. You need publications in prestigious journals, sterling recommendations, and a bulletproof research plan—and even then, don’t feel too good about your chances. Top universities receive hundreds of similarly qualified applicants for every opening, meaning you'll likely need to apply nationwide and be prepared to move across the country if you're fortunate enough to receive an offer.
So why would anyone willingly pursue this path? Everyone has their own reasons, but most cite some combination of stability, freedom, and mentorship.
Stability has traditionally been academia's crown jewel. Unlike biotech’s boom-and-bust cycles, tenure offers lifetime security once you establish yourself. Stability, in turn, enables freedom—the autonomy to explore understudied areas, commit years to emerging technologies, or pivot entirely to new avenues, all without immediate commercial pressures. Finally, there’s mentorship. Science is inherently uncertain: not every direction succeeds, nor does every scientist earn a Nobel Prize. But mentoring the next generation multiplies your impact far beyond what you could achieve alone.
For years, academia felt like the ideal place for me to explore the ambitious ideas outlined here. Developing transformative technologies thrives in an environment with fresh insights from students, freedom to explore multiple paths, and thoughtful consideration of long-term impact rather than immediate profitability.
But today, the three pillars of academia—stability, freedom, and mentorship—are crumbling. The NIH is in shambles, universities have instituted indefinite hiring freezes, and grants are being abruptly canceled under political pretenses. Good luck explaining to your students that you might not be able to pay them next month.
Many prominent voices, including Nobel Laureate David Baker, warn that these deteriorating conditions disproportionately harm scientists in transition—graduate students, postdocs, and early-career faculty. But besides established faculty, we're all eventually expected to move on to the next step. If this continues, we're at risk of losing an entire generation of scientific talent.
I fear I may become part of that lost generation. Even if I do receive a faculty offer, the current circumstances make accepting it uncertain.
But this isn’t just about me. Behind every postdoc is a decade of sacrifice and a unique vision for solving some of humanity’s most profound challenges. Statistics can’t capture the human reality of what we’re losing. I see it daily in my colleagues—brilliant scientists who've persevered through personal hardships, family illnesses, poverty-level stipends, and a global pandemic. They endured not for wealth or recognition, but because they glimpsed ways to make the world better. Yet we may be approaching a breaking point that drives many from academia permanently.
That's the true tragedy of this moment. We're not just losing individual scientists; we're losing entire futures, unexplored realms of knowledge, and potential breakthroughs that could have transformed human health and biology.
Against that bleak backdrop, this essay is a small act of rebellion, a message in a bottle tossed into the coming storm.
Further reading
Spatial technologies of the future, Zack Chiang
The Song of the Cell, Siddhartha Mukherjee
Replacing Aging, Jean Hébert
In Vivo Cellular Reprogramming: The Next Generation, Deepak Srivastava and Natalie DeWitt
Cell maturation: Hallmarks, triggers, and manipulation, Juan R. Alvarez-Dominguez and Douglas A. Melton
Expansion in situ genome sequencing would be very useful to study chromosome dynamics during meiosis. If you'd like to collaborate please let me know.